- Best Undergraduate Thesis Award, HUST. (10/220)
- Download ZIP File (in Chinese)
- View On GitHub
Sharp Search is a personalized search engine which can automatically optimize the retrieval quality of search using clickthrough data. The initial motivation is from my work @ Innovation Engineering Group in Microsoft Research, where I investigated the Server log of "Travel Guide" project.
Intuitively, a good information retrieval system should present relevant documents high in the ranking, with less relevant documents following below. A traditional method to evaluate the relevance is based on text mining, such as "PageRank", "Topic Model", "TF-IDF" and so on. However, another possibility lies in exploring the HCI side of IR - how people use the search engine. In this project, I focused on the clickthough data in a search engine, and re-calculate the relevance score based on my click history.
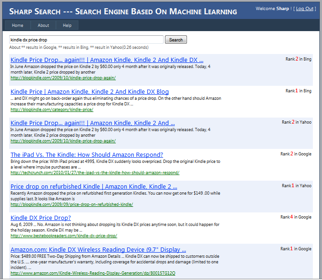
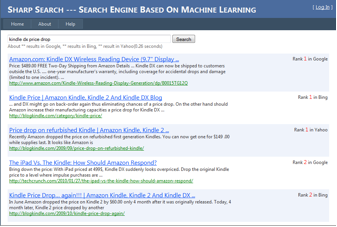
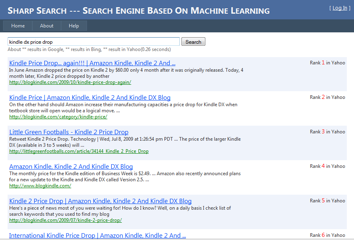
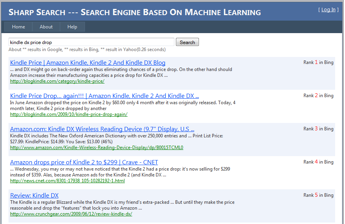
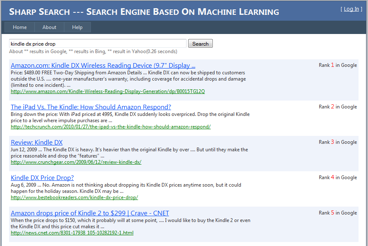
Here is a screenshot of this project.

In most case, searchers usually scanned the ranking from top to bottom. When a user clicks the 3rd link firstly, she must have observed 1st & 2nd result and made the decision to not click it. Given that the abstracts presented with the links are sufficiently informative, this gives some indications of the users' preference. Similarly, if a user clicks on link 1, 3, 7, it could infer that link 7 is more relevant than link 2, 4, 5 and 6.
When a user types a query into Sharp Search's interface, the query would be forwarded to "Google", "Yahoo" and "Bing". Sharp Search would extract top 100 search results from the result pages in these 3 search engines (HTML - parser based). The union of results composes the candidate set V, and a SVM retrieval function would re-rank these results according to the click-through data. All the user behavior data were recorded by Javascript and stored in Internet Information Service Log files.
rank info:
rank_i_X: i=rank; X={Google, Bing, Yahoo}
domain info: top_i_domain
query url similarity: query_url_cosine; query_summery_cosine; query_title_cosine:
.......
From May 3rd to June 3rd 2010, I hosted Sharp search on my laptop and collected all my search queries and behavior data during that time (290 search queries, 1172 clickthrough history).
evaluation:| Bing | Yahoo | Sharp Search | ||
| Lucky Count | 55 | 38 | 37 | 61 |
| Top 10 Average Count | 5.3 | 4.8 | 5.5 | 6.4 |
| Top feature | Weight |
| query_url_cosine | 0.50 |
| top_10_google | 0.30 |
| query_title_cosine | 0.28 |
| top_10_count_3 | 0.24 |
| top_1_google | 0.18 |
| .... | .... |
| .... | .... |
| url_domain_tw | -0.17 |
| url_length | -0.25 |
| top_10_count_0 | 0.45 |
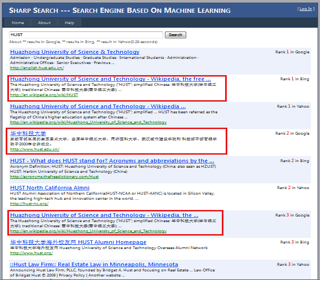
More screenshots can be found in the zip documents.